背景介绍
我使用Evernote已近10年,虽然不是每天都在Evernote中工作,但也可以算作一个中度依赖者。为了利用Evernote提高生活、工作的便捷性,也尝试按照自己的需求完善Evernote,比如这篇博客Evernote To-do List 自动同步 Google Calendar 方法。
我一直使用的都是Evernote国际版,印象笔记我是没有碰的,至于原因想必看到我博客的朋友应该都可以明白,天朝特殊化后的IT产品必须要摒弃之,尽管我没有任何真正需要隐藏的信息。印象笔记的定价我个人是可以接受的,但2016年后Everonte国际版针对中国大陆地区的价格变得和美国一样了,这样的价格就非常的高了。虽然我是愿意购买互联网服务的,但是价格得公平合理,作为中国用户,我只愿意支付和印象笔记相同的金额来使用Evernote。2016年我通过VPN使用了印度的IP购买了Evernote的服务,印度的价格与印象笔记差不多,用了几年。
2020年7月份,旧信用卡到期,更新信用卡信息后发现,Evernote完善了它的支付系统,支付地址所在国家必须和IP地址所在国家一致,否则无法支付。经过和Evernote客服的沟通,要求提供和印象笔记相同的价位无果后,终于做出了替换掉Evernote的决定。
需求分析
作为一个开源软件的爱好者,自然而然得会对自由、隐私保护特别留意。将个人笔记这种非常隐私的内容放在Evernote这种数据由第三方美国公司管理的地方一直都是一个心结,虽然我并没有什么秘密 :)。借着这次机会,重新打造一个自己的笔记、资料存储系统,分析一下需求。
- 数据完全由自己控制,最好支持加密;
- 跨平台同步,平台支持越多越好,Windows, Linux, Andorid是必须的;
- 对笔记的管理方式类似于Evernote,但笔记本应该可以支持多层级(超过2级,这是Evernote使用过程中的痛点);
- 笔记中可以方便得存放附件,允许对附件使用第三方软件进行编辑;
- 信息可以通过多渠道汇入笔记系统,WebCliper、Email、Android share等;
- 创建的 to-do or appointment 笔记最好可以同步在日历上;
- 最好可以直接将笔记Email出去。
回忆一下自己使用Evernote的过程,主要需求就是这些,其它的杂项,比如音频笔记、绘图功能、Web Client其实几乎没有真正用到过。至于分享、团队协作等功能我个人用不到,我的笔记系统是私人的笔记本。
寻找替代品
明确了自己的需要,便开始在网上搜索目前出现的其它笔记软件,查询了一下,现在市面上的笔记软件真多,包括收费和免费的几十种有了,具体的名字这里就不一一罗列了。但没有一种能完全符合我上面的需求。经过一番横向的对比分析,找到了目前和Evernote最为接近的一款软件–Joplin,决定尝试一下。
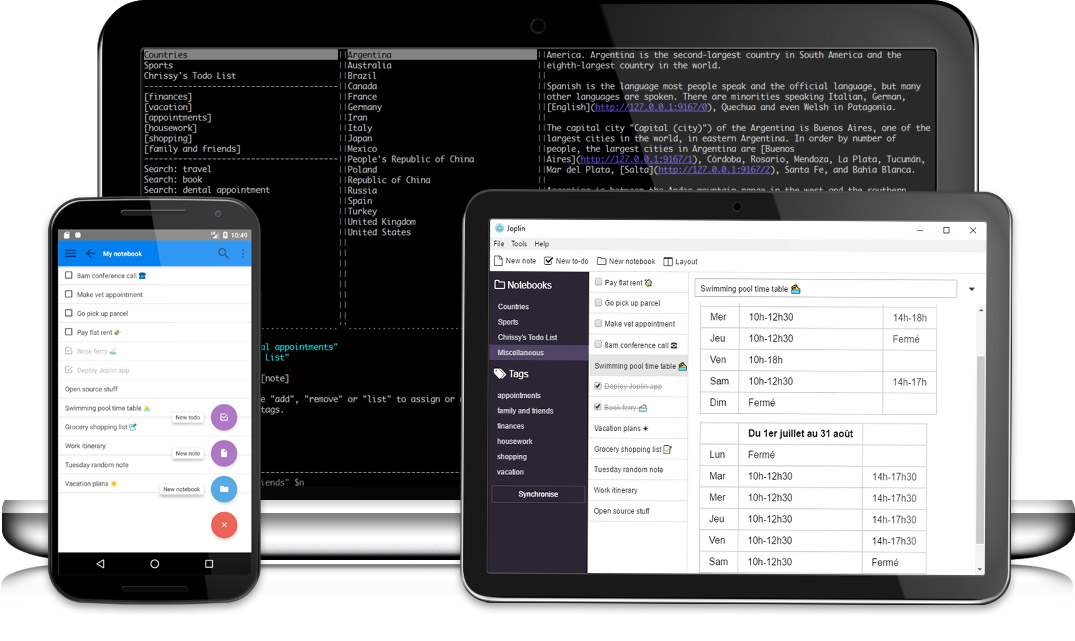
Joplin的主要特点
- 开源软件,不用担心数据被偷偷上传到某个公司的服务器上去;
- 支持几乎所有的平台,包含Linux,甚至还带有Linux terminal 程序,满足Geek的同时也让Joplin有被写入脚本,从而 按不同需要实现自动化操作的潜力。这一点直接秒杀了几乎所有的收费软件;
- 数据完全由用户控制,同步系统采用了纯文件的形式进行管理,有好出也有弊端。好处是省去了专有的服务器程序,通过普通的文件操作就可以对同步系统进行控制,Joplin自带了对文件系统、NextCloud、WebDav、Dropbox、oneDrive、S3的支持;坏处是产生大量的小文件,很多文件系统中会造成磁盘空间的浪费,更要命的是网络传输小文件慢,导致同步速率太低;
- 支持多级目录和Markdown,对原创性写作,使用起来比Evernote要好;
- 软件内可以实现瞬间搜索;
- 支持网页采集Webclipper;
- 支持加密,即使使用第三方的存储系统也不会泄漏数据。
我的Jopin设定
针对Joplin的特点和我自己的需要,最开始我尝试了自己搭建Webdav服务器,然后让Joplin通过WebDav的接口来实现同步,功能性上没有问题,也确保了数据在自己的服务器上,但一个恼人的问题就是同步速度太慢!如果放弃隐私,将数据提交到dropbox或oneDrive,发现传输速率也没有任何改善,甚至更慢。
简单直白的方式无法达到目的就只能复杂化了。于是决定利用syncThing这个高效的开源P2P同步软件来帮助Joplin同步数据,该软件甚至在Andorid手机上也能完美工作。
syncThing的安装和用法这里就不介绍了,不属于本文的主题,需要的朋友自行搜索吧。安装好syncThing后,设定syncThing要进行同步的目录,再将Joplin的同步方式选定为“文件系统”,指定目录为syncThing的同步目录。这样就解决了Joplin同步慢的问题。在这里要注意的是:
- 在需要使用Joplin的不同机器上,先设定syncThing的同步目录;
- 再通过1台机器设定Joplin的同步目录,导入以前的笔记,完成数据上传。syncThing会自动将同步数据同步到不通的机器上;
- 在其它机器上设定Joplin,将同步目录设定到syncThing的同步目录上。Joplin会自动下载笔记,完成同步。注意:如果后来加入的机器之前用过Joplin,那同步前必须将本机Joplin的数据文件清空。
这样的方式存在一个问题,如果刚刚操作的电脑关机了,那手机上或其它电脑上就无法获得最新的数据了。因而我们需要至少1台服务器,上面也运行syncThing来同步数据。因为syncThing P2P的特点,我在家中的NAS系统和公网上的服务器中都设定了同步点,尽可能保证同步效果。
关于备份
自己管理笔记系统一个要注意的地方就是数据的备份,万一一个误操作,自己多年的数据可能全部丢失,而且是自己造成的,索赔和发泄都没有地方。我们不能将不通设备作为笔记的备份点 ,因为它们之间是同步的,一个节点数据丢失,瞬间会导致其它节点上的数据被删除。
因此备份数据应该被打包存放在一台不参与同步的机器上。这里我推荐一个数据备份服务给大家B2 Cloud Storage,性能稳定,价格低廉,我已使用多年。在VPS服务器中写个脚本 将syncThing同步目录打包加密后上传至B2备份节点中即可。可以安心地睡觉了。
邮件支持的痛点
在使用Evernote的过程中习惯了将工作上的邮件自动保存进笔记系统的Inbox笔记本中,然后挑选需要做的事情,并移动到TO-DO笔记本中,从而提高GTD的工作效率(我很懒,从邮件粘贴内容到笔记中,再添加附件都觉得累)。
问题是Joplin是完完全全自架的软件,没有专门的服务器后端程序,更不可能去提供一个临时邮件地址来接收邮件并转化成笔记了。这感觉很不爽,但Joplin是一个完善的程序,提供了API和终端程序 ,这样就为功能的扩展提供了可能性。
我的解决方案
用开源软件的Geek,需要做的事情就是重复发明轮子来满足自己的需要。
思路
利用24小时在线的VPS,写一个脚本将某个专用信箱中的邮件收取下来,然后利用Joplin terminal 程序,将邮件自动转变成笔记,再通过syncthing自动同步到其它客户端。思路清晰了,那就动手实现,下面将一些需要注意的地方总结一下。
Joplin terminal 安装注意事项
官方页面中对Joplin terminal程序的安装介绍得有些过于简单,对于一个干净的系统,按照官方页面的信息会因为缺少必要的包而导致安装事败。安装Joplin terminal之前需要先安装git和libsecret-devel包。如:
- 需要先安装git
yum install git - 需要安装libsecret-devel包
yum install libsecret-devel - 安装nodejs,版本要在10以上
- 最后通过npm安装(–unsafe-perm不建议开启,使用root安装出现问题时才用)
NPM_CONFIG_PREFIX=~/.joplin-bin npm install -g --unsafe-perm joplin
Joplin terminal安装好后,我们利用Python脚本来完成剩下的工作。这里我临时注册了一个GMAIL作为接收笔记的专用信箱,并且开启了IMAP和允许“不安全程序访问”等选项。参考网上 代码写了一个Python脚本,该Python脚本会从IMAP服务器中下载所有邮件,提取出邮件标题、发送人、邮件正文以及附件。然后将这些内容重新组合创建出一个新的笔记。众所周知,处理邮件中中文编码比较麻烦,本代码基本上可以处理大多数情况。
PS:自己用的小程序,大牛勿喷。
将邮件转变为笔记的python3 完整代码:
#!/usr/bin/python3
import imaplib
import email
import os
import subprocess
import re
import shutil
from datetime import datetime
# 转换编码
def decode_str(str_in):
value, charset = email.header.decode_header(str_in)[0]
if charset:
value = value.decode(charset)
return value
# 猜测编码
def guess_charset(msg):
# 先从msg对象获取编码:
charset = msg.get_content_charset()
if charset is None:
# 如果获取不到,再从Content-Type字段获取:
content_type = msg.get('Content-Type', '').lower()
pos = content_type.find('charset=')
if pos >= 0:
charset = content_type[pos + 8:].strip()
return charset
# 设定服务器信息
server = 'imap.gmail.com'
port = 993
username = 'account@gmail.com'
password = 'password'
attachmentPath = '/tmp/mail-attach/'
# 定义全局变量
noteId = ''
email_subject = ''
body_content = ''
email_from = ''
attachedFiles = list()
# 打印运行时间
now = datetime.now()
print(now)
if os.path.exists(attachmentPath):
shutil.rmtree(attachmentPath)
# 下载邮件前做必要的Joplin工作(1.同步 2.选定笔记本)
try:
print("joplin sync ...")
out_text = subprocess.check_output(['joplin', 'sync']).decode('utf-8')
print("Done.")
out_text = subprocess.check_output(['joplin', 'use', '0.Inbox'])
print("Picked Notebook '0.Inbox'.")
except subprocess.CalledProcessError as e:
out_text = e.output.decode('utf-8')
rtcode = e.returncode
if rtcode != 0:
print("Joplin sync failed! Exit...")
exit(-1)
# 链接服务器
conn = imaplib.IMAP4_SSL(server, port)
print("Connected to IMAP server.")
conn.login(username, password)
print("Logged in.")
conn.select('Inbox')
print("Selecet 'Inbox' folder on the IMAP server.")
# 收取所有邮件
status, data = conn.search(None, 'All')
mailIds = data[0].split()
num = 0
for mailId in mailIds:
print("\n--------Processing mail {} ---------".format(num))
num += 1
status, rawMsg = conn.fetch(mailId, '(RFC822)')
rawMail = rawMsg[0][1]
raw_email_string = rawMail.decode('utf-8', 'ignore')
msg = email.message_from_string(raw_email_string)
# 获取邮件标题
rawSub = msg.get('subject')
header = email.header.Header(rawSub)
decodedHeader = email.header.decode_header(header)
email_subject = decodedHeader[0][0]
if decodedHeader[0][1]:
email_subject = decode_str(str(email_subject, decodedHeader[0][1]))
if isinstance(email_subject, bytes):
email_subject=email_subject.decode()
print("Processing email "+email_subject+"...")
# 获取邮件发送人
rawFrom = msg.get('from')
header = email.header.Header(rawFrom)
decodedHeader = email.header.decode_header(header)
email_from = decodedHeader[0][0]
if decodedHeader[0][1]:
email_from = decode_str(str(email_from, decodedHeader[0][1]))
if isinstance(email_from, bytes):
email_from = email_from.decode()
# 清空attachedFiles列表
attachedFiles.clear()
attachedFile = ''
# 获取当前邮件主体
for part in msg.walk():
if part.is_multipart():
continue
if not part.is_multipart():
body_type = part.get_content_type()
print(body_type)
if body_type == 'text/plain' or body_type == 'text/html':
# 对邮件正文进行解码
body_charset = guess_charset(part)
body_content = part.get_payload(decode=True).decode(body_charset, 'ignore')
# 判断已经解码的字符串是不是unicode转义的
# 如果是,则需要利用'unicode_escape'重新解码
pattern = r'\\u[0-9A-Fa-f]'
strType = re.search(pattern, body_content)
if strType is not None:
body_content = body_content.encode('utf-8').decode('unicode_escape', 'replace')
else:
# 保存附件
fileName = part.get_filename()
if fileName:
header = email.header.Header(fileName)
# 对附件名称进行解码
decodedHeader = email.header.decode_header(header)
fileName = decodedHeader[0][0]
if decodedHeader[0][1]:
# 将附件名称可读化
fileName = decode_str(str(fileName, decodedHeader[0][1]))
if bool(fileName):
if not os.path.exists(attachmentPath):
os.makedirs(attachmentPath)
filePath = os.path.join(attachmentPath, fileName)
# 保存附件,有同名文件进行覆盖
fp = open(filePath, 'wb')
fp.write(part.get_payload(decode=True))
fp.close()
attachedFiles.append(filePath)
# 已获取当前邮件的数据,将改邮件标记为删除
conn.store(mailId, '+FLAGS', r'(\Deleted)')
print("Email " + email_subject + " was marked to delete.")
# 将收取到一封的邮件导入Joplin-bin
try:
# 创建一个空笔记
out_text = subprocess.check_output(['joplin', 'mknote', email_subject]).decode('utf-8')
print("Note " + email_subject + " created.")
# 找到该孔笔记的ID
out_text = subprocess.check_output(['joplin', 'ls', '-l']).decode('utf-8')
for line in out_text.splitlines():
if line.find(email_subject) == -1:
continue
else:
noteId = line[0:4]
# 设定笔记内容
out_text = subprocess.check_output(['joplin', 'set', noteId, 'body', body_content])
print("Wrote content for note " + email_subject + ".")
# 设定笔记是HTML形式
out_text = subprocess.check_output(['joplin', 'set', noteId, 'markup_language', '1'])
print("Set note " + email_subject + " to Markdown format, so that HTML and MD both are OK.")
# 设定笔记的source
out_text = subprocess.check_output(['joplin', 'set', noteId, 'source', 'Email'])
print("Set note " + email_subject + "'s source to 'Email'.")
# 设定笔记的作者为邮件发送人
out_text = subprocess.check_output(['joplin', 'set', noteId, 'author', email_from])
print("Set note " + email_subject + "'s author to " + email_from + ".")
# 设定笔记的Tag为Emailed
out_text = subprocess.check_output(['joplin', 'tag', 'add', 'Emailed', noteId])
print("Add Tag 'Emailed' to note " + email_subject + ".")
# 有附件的情况下向笔记中插入附件
for attachedFile in attachedFiles:
out_text = subprocess.check_output(['joplin', 'attach', noteId, attachedFile])
print("Added attachment " + attachedFile + " to Note "+email_subject+".")
except subprocess.CalledProcessError as e:
out_text = e.output.decode('utf-8')
rtcode = e.returncode
if rtcode != 0:
print("Joplin operations failed! Exit...")
exit(-1)
# Joplin操作完毕,删除临时保存的当前邮件的附件
for attachedFile in attachedFiles:
if os.path.exists(attachedFile):
print("Deleting file " + attachedFile + " ...")
os.remove(attachedFile)
else:
print("Error: Deleting "+attachedFile+" failed!")
# 删除IMAP服务器上的所有邮件,以免重复创建笔记
print("Deleting mails from IMAP server.")
conn.expunge()
conn.close()
conn.logout()
# 所有笔记已经创建完毕,进行同步
try:
print("joplin sync ...")
out_text = subprocess.check_output(['joplin', 'sync'])
print("Job done.")
except subprocess.CalledProcessError as e:
rtcode = e.returncode
if rtcode != 0:
print("Joplin sync failed!")
exit(-1)
最后将该PYTHON程序放入cron计划任务中,每5分钟执行一次即可。
友情提示:
- Python在crontab中运行时有很多问题,丢失环境变量会导致运行正常的脚本出错,可以写一个bash脚本,设定环境变量,再在bash脚本中启动python脚本;
- 编码问题,因为有中文,需要在corntab的命令开始加入’LANG=zh-CN.UTF-8’,防止脚本运行时被迫中断。
- Joplin目前有一个bug,删掉笔记后,原笔记中的附件文件很容易变成垃圾文件,造成数据越来越大。好在有人写出了清理Joplin垃圾的脚本,只要对Joplin的同步文件夹进行扫描清理即可。JoplinClean
这样一个支持Email汇入的私人笔记系统就打造好了。整体工作稳定,虽然便利程度依然没有Evernote高,但在隐私保护和可用性两方面都考虑的情况下,Joplin已经非常出色了。如果你也在找Evernote的替代品,希望本文帮助到了你 。